Machine learning methods are very good at dealing with overfitting, that is, the tendency of statistical models to accurately fit previously seen data and to poorly predict previously unseen data.
![]()
Remember that we have defined a
predictive model as a
function
![]() that takes an input
that takes an input
![]() as argument and returns a prediction
as argument and returns a prediction
![]() of the true output
of the true output
![]() .
.
In what follows, we are going to deal with parametric models, that is,
families of models
![]() indexed by a parameter vector
indexed by a parameter vector
![]() .
.
In a parametric model, predicted outputs depend on the parameter and so do
losses
![]() ,
the risk
,
the risk
![]() and the empirical risk
and the empirical risk
![]() .
.
Typical examples of parametric models are:
a linear regression
model
![]() where
the input
where
the input
![]() is a
is a
![]() row vector and the parameter
row vector and the parameter
![]() is a
is a
![]() vector of regression coefficients;
vector of regression coefficients;
a
logistic
classification model
![]() where
where
![]() is the logistic function.
is the logistic function.
When we estimate the parameter
![]() naively by empirical risk minimization, we search for a solution of the
problem
naively by empirical risk minimization, we search for a solution of the
problem
![]()
But this is equivalent to
![]()
Thus, we are minimizing the sum of two terms:
the true risk of the predictive model
![]() ;
;
the term
![]() ,
which is a measure of the reliability of the empirical risk
,
which is a measure of the reliability of the empirical risk
![]() as an estimate of the true risk
as an estimate of the true risk
![]() .
The smaller this term is, the more
.
The smaller this term is, the more
![]() under-estimates the true risk (the less its reliability).
under-estimates the true risk (the less its reliability).
Clearly, we would like to minimize only the first term, while minimizing the second one (reliability) is detrimental. Unfortunately, we are minimizing both!
There is no general way to tell how much the second term contributes to the
minimum we attain, but in certain cases its contribution can be substantial.
In other words, our estimate of the expected loss, performed with the same
sample used to estimate
![]() ,
can be over-optimistic. This is called overfitting.
,
can be over-optimistic. This is called overfitting.
In the above formulae, we can replace
![]() with
with
![]() ,
the average loss on a sample (so-called test sample) different from the one
used to estimate
,
the average loss on a sample (so-called test sample) different from the one
used to estimate
![]() (so-called estimation or training sample). By doing so, we can see that, when
we perform empirical risk minimization naively, we are also maximizing the
disappointment experienced on the test sample.
(so-called estimation or training sample). By doing so, we can see that, when
we perform empirical risk minimization naively, we are also maximizing the
disappointment experienced on the test sample.
Another way to see the overfitting problem is that the empirical risk provides a biased estimate of the true risk when it is computed with the same sample used to train our models.
Important: when the predictive model is a linear regression model and the loss function is the squared error, then naive empirical risk minimization is the same as OLS (ordinary least squares) estimation. In this case the bias of the empirical risk can be derived analytically.
What machine learning does: in the typical machine learning workflow, overfitting is constantly kept under control during the minimization process, so as to avoid it as much as possible.
Typically, but not
necessarily, overfitting tends to be more severe when models are highly
complex (i.e., the dimension of the parameter vector
![]() is large).
is large).
A classical example is provided by a simple linear regression of few data points on time vs a more complex linear regression on time and several of its powers (polynomial terms).
A more complex model typically has better in-sample performance...
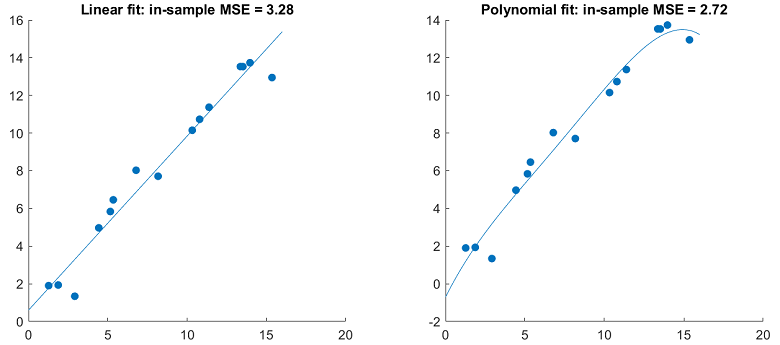
... but worse out-sample performance
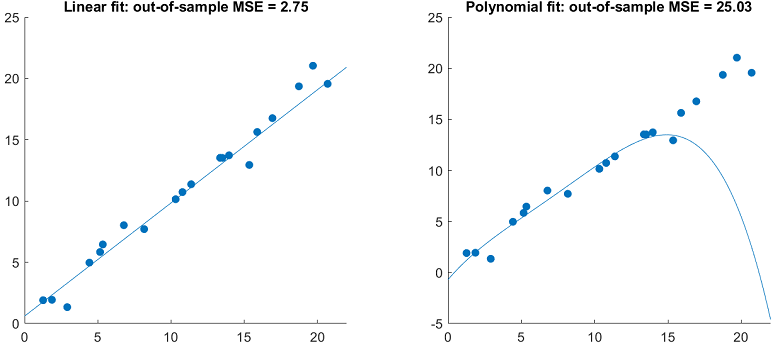
A reason why models with many parameters tend to overfit is that they are affected by the so-called curse of dimensionality.
For concreteness, suppose that the number of parameters is the same as the number of output variables, as in linear regression (where the number of regressors is equal to the number of regression coefficients, which are the parameters to be estimated).
The percentage of regions of the space of outputs covered by our data set decreases exponentially in the number of outputs (and parameters).
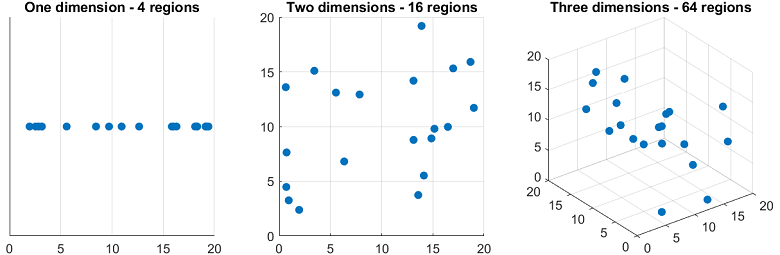
As a consequence, as we increase the dimensionality of our model, we increase the probability that new data points (out-of-sample data) will belong to regions of space that were not covered by the training/estimation data and where things may work very differently than in the regions that were covered.
This exponential decrease in coverage is called curse of dimensionality.
A related phenomenon is that the average distance between new points and the points belonging to the estimation sample tends to increase with the dimension of the model.
Further insights about the possible pitfalls of highly parametrized models can be derived from the so-called bias-variance decomposition.
Suppose that the loss function is the squared error.
Then, the best possible prediction of
![]() is the
conditional
expectation
is the
conditional
expectation
![]()
It can be proved that
![[eq18]](/images/overfitting__32.png) which
is called bias-variance decomposition.
which
is called bias-variance decomposition.
In other words, the risk of a model is the sum of three terms:
the irreducible error, due to the fact that
![]() may not contain all the information that is needed to perfectly predict
may not contain all the information that is needed to perfectly predict
![]() ;
;
the bias, generated by systematic differences between the
model predictions
![]() and the best possible predictions
and the best possible predictions
![]() ;
;
the variance, due to the fact that the parameters of our
predictive models and hence the predictions
![]() are affected by sampling variability.
are affected by sampling variability.
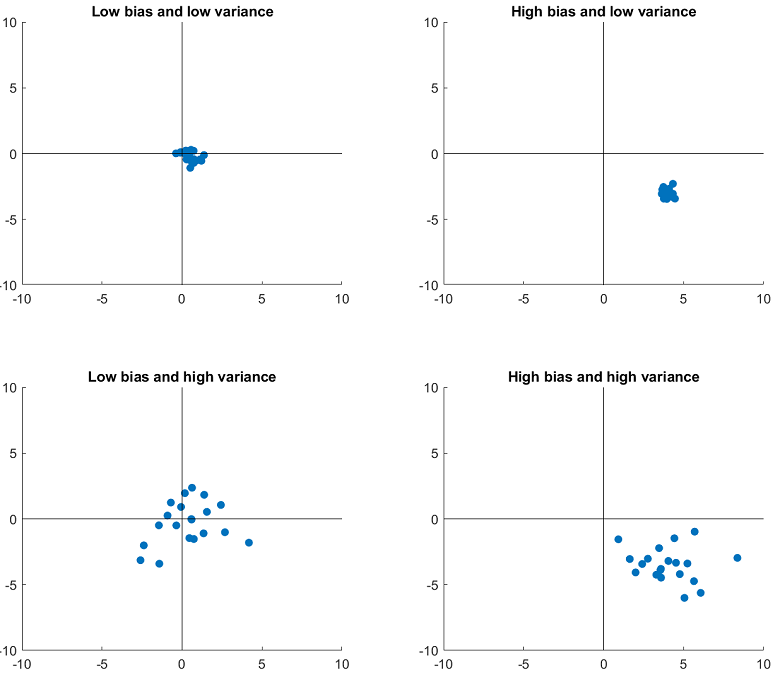
It turns out that in many settings variance is an increasing function of model complexity (number of parameters), while bias is a decreasing function. As a consequence, there is a trade-off between the two.
Beyond the point of optimal balance between the two (i.e., if complexity is increased too much), performance degrades.
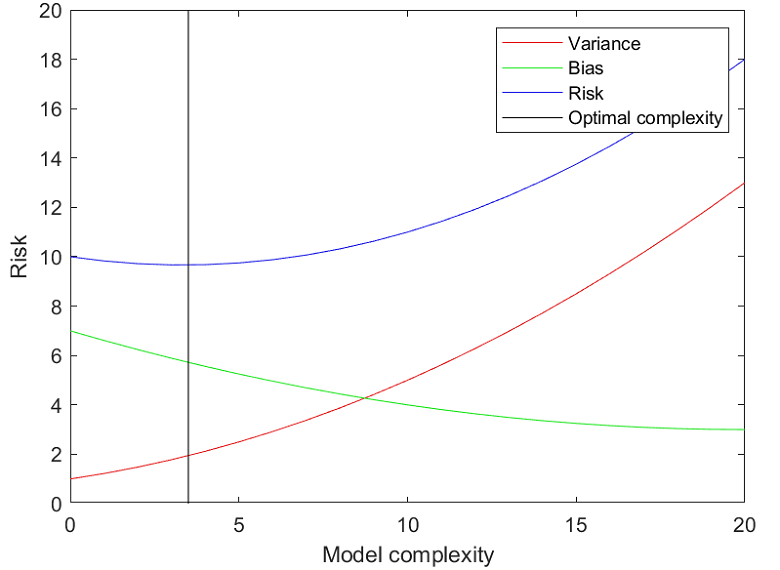
In linear regression with
![]() regressors (and zero-mean variables), the true vector of regression
coefficients is
regressors (and zero-mean variables), the true vector of regression
coefficients is
![]() where:
where:
![]() is the
is the
![]() covariance matrix of inputs
covariance matrix of inputs
![]() ;
;
![]() is the
is the
![]() vector of covariances between inputs
vector of covariances between inputs
![]() and outputs
and outputs
![]() .
.
The OLS estimator is
![]() where
the matrix
where
the matrix
![]() and the vector
and the vector
![]() are obtained by stacking inputs and outputs.
are obtained by stacking inputs and outputs.
Roughly speaking,
![]() estimates
estimates
![]() and
and
![]() estimates
estimates
![]() .
.
The number of
covariances to estimate
(and potential sources of error in estimating
![]() )
is
)
is
![]() .
Hence, it grows with
.
Hence, it grows with
![]() .
.
The fact that the sources of error grow with the square of the number of parameters is one of the reasons why OLS regressions with many regressors overfit data and work poorly (unless you have tons of data).
An important thing to note is that all of the aforementioned problems are very severe with small sample sizes, but they tend to become less severe when the sample size increases:
empirical risk tends to become a more reliable estimate of true risk (by the Law of Large Numbers); hence, over-fitting decreases;
the curse of dimensionality becomes less of a problem (because more and more regions of space are covered by the sample);
the variance (in the bias-variance decomposition) decreases because there is less sampling variability.
Please cite as:
Taboga, Marco (2021). "Overfitting", Lectures on machine learning. https://www.statlect.com/machine-learning/overfitting.
Most of the learning materials found on this website are now available in a traditional textbook format.