A Law of Large Numbers (LLN) is a proposition that provides a set of sufficient conditions for the convergence of the sample mean to a constant.
Typically, the constant is the expected value of the distribution from which the sample has been drawn.
![]()
Let
![]() be a sequence of random variables.
be a sequence of random variables.
Let
![]() be the sample mean of the first
be the sample mean of the first
![]() terms of the
sequence:
terms of the
sequence:![[eq2]](data:image/gif;base64,R0lGODlhAQABAIAAANvf7wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)
A Law of Large Numbers (LLN) states some conditions that are
sufficient to guarantee the convergence of
![]() to a constant, as the sample size
to a constant, as the sample size
![]() increases.
increases.
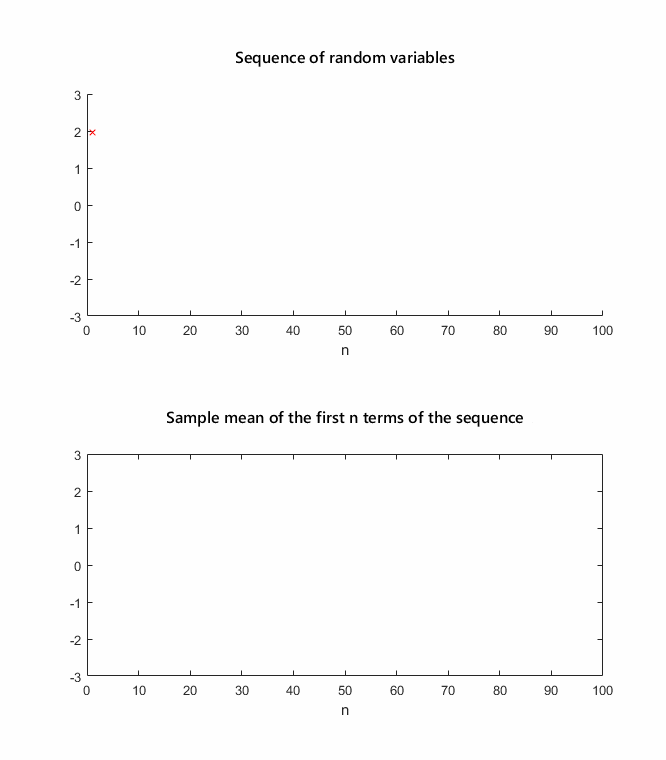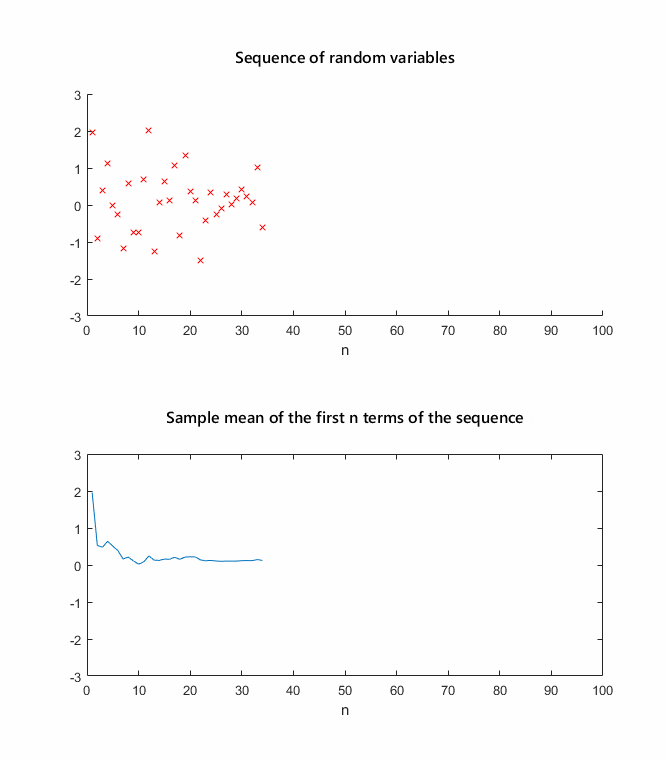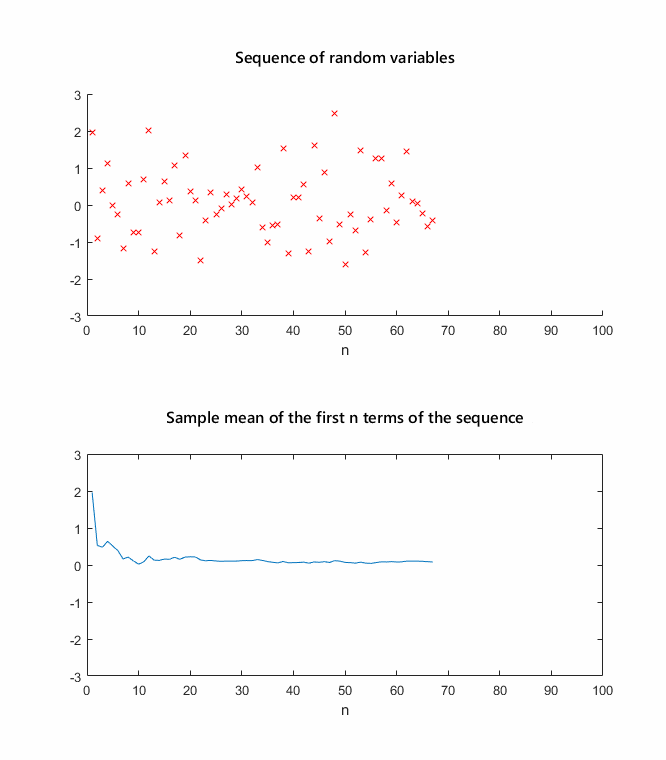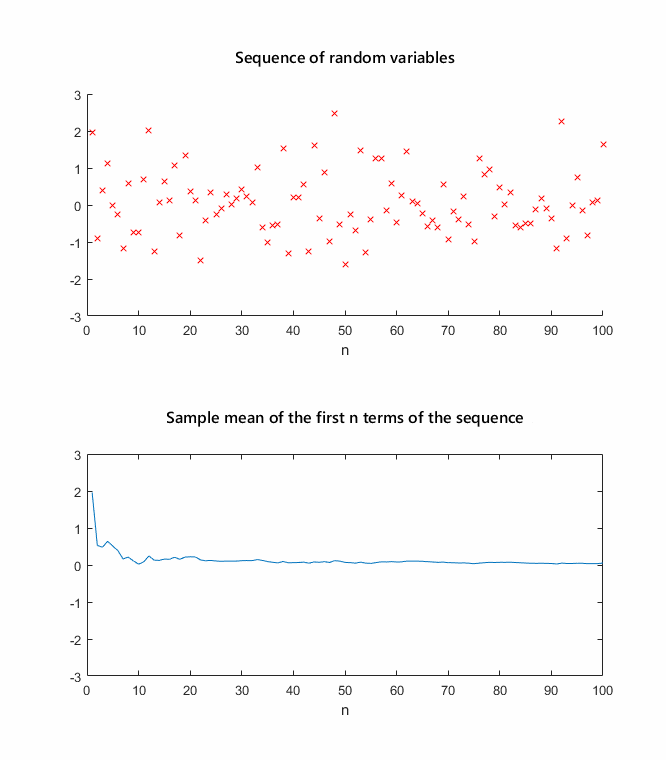
Typically, all the random variables in the sequence
![]() have the same expected value
have the same expected value
![]() .
In this case, the constant to which the sample mean converges is
.
In this case, the constant to which the sample mean converges is
![]() (which is called population mean).
(which is called population mean).
But there are also Laws of Large Numbers in which the terms of the sequence
![]() are not required to have the same expected value. In these cases, which are
not treated in this lecture, the constant to which the sample mean converges
is an average of the expected values of the individual terms of the sequence
are not required to have the same expected value. In these cases, which are
not treated in this lecture, the constant to which the sample mean converges
is an average of the expected values of the individual terms of the sequence
![]() .
.
There are literally dozens of LLNs. We report some important examples below (road map in the figure).
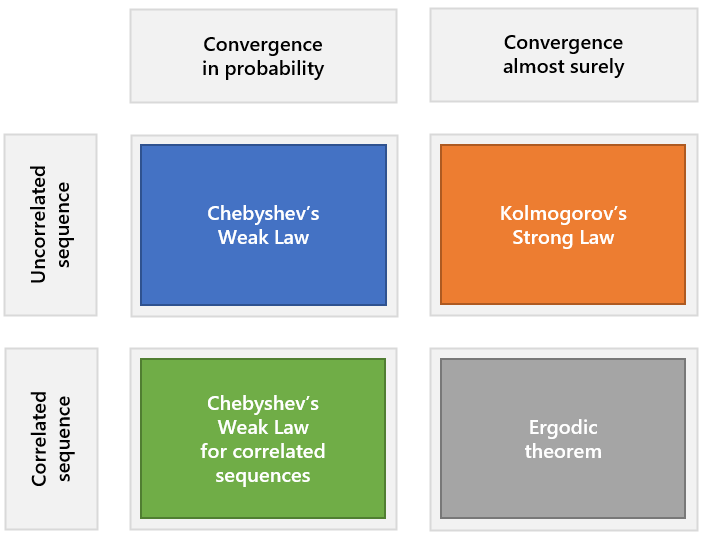
A LLN is called a Weak Law of Large Numbers (WLLN) if the sample mean converges in probability.
The adjective weak is used because convergence in probability is often called weak convergence. It is employed to make a distinction from Strong Laws of Large Numbers, in which the sample mean is required to converge almost surely.

One of the best known WLLNs is Chebyshev's.
Proposition (Chebyshev's
WLLN)
Let
![]() be an uncorrelated and
covariance stationary
sequence:Then,
a Weak Law of Large Numbers applies to the sample
mean:where
be an uncorrelated and
covariance stationary
sequence:Then,
a Weak Law of Large Numbers applies to the sample
mean:where
![]() denotes a probability limit.
denotes a probability limit.
The expected value of the sample mean
![]() isThe
variance of the sample mean
isThe
variance of the sample mean
![]() is
is![[eq11]](/images/law-of-large-numbers__19.png) Now
we can apply Chebyshev's
inequality to the sample mean
Now
we can apply Chebyshev's
inequality to the sample mean
![]() :for
any
:for
any
![]() (i.e., for any strictly positive real number
(i.e., for any strictly positive real number
![]() ).
Plugging in the values for the expected value and the variance derived above,
we
obtainSinceand
).
Plugging in the values for the expected value and the variance derived above,
we
obtainSinceand![]() then
it must be that
also
then
it must be that
also![]() Note
that this holds for any arbitrarily small
Note
that this holds for any arbitrarily small
![]() .
By the very definition of convergence in
probability, this means that
.
By the very definition of convergence in
probability, this means that
![]() converges in probability to
converges in probability to
![]() (if you are wondering about strict and weak inequalities here and in the
definition of convergence in probability, note that
(if you are wondering about strict and weak inequalities here and in the
definition of convergence in probability, note that
![]() implies
implies
![]() for any strictly positive
for any strictly positive
![]() ).
).
Note that it is customary to state Chebyshev's Weak Law of Large Numbers as a
result on the convergence in probability of the sample
mean:
However, the conditions of the above theorem guarantee the
mean square convergence of the sample mean to
![]() :
:![]()
In the above proof of Chebyshev's WLLN, it
is proved
that![]() and
that
and
that
![]() This
implies
that
This
implies
that![]() As
a
consequence,
As
a
consequence,![]() but
this is just the definition of mean square convergence of
but
this is just the definition of mean square convergence of
![]() to
to
![]() .
.
Hence, in Chebyshev's WLLN, convergence in probability is just a consequence of the fact that convergence in mean square implies convergence in probability.
Chebyshev's WLLN sets forth the requirement that the
terms of the sequence
![]() have zero covariance with each other. By relaxing this requirement and
allowing for some correlation between the terms of the sequence
have zero covariance with each other. By relaxing this requirement and
allowing for some correlation between the terms of the sequence
![]() ,
a more general version of Chebyshev's Weak Law of Large Numbers can be
obtained.
,
a more general version of Chebyshev's Weak Law of Large Numbers can be
obtained.
Proposition (Chebyshev's WLLN for correlated
sequences)
Let
![]() be a covariance stationary sequence of random
variables:If
covariances tend to be zero on average, that is,
ifthen
a Weak Law of Large Numbers applies to the sample
mean:
be a covariance stationary sequence of random
variables:If
covariances tend to be zero on average, that is,
ifthen
a Weak Law of Large Numbers applies to the sample
mean:
For a full proof see, e.g.,
Karlin and Taylor (1975). We give here a proof
based on the assumption that covariances are absolutely
summable:which
is a stronger assumption than the assumption made in the proposition that
covariances tend to be zero on average. The expected value of the sample mean
![]() isThe
variance of the sample mean
isThe
variance of the sample mean
![]() is
is![[eq34]](/images/law-of-large-numbers__53.png) Note
that
Note
that
![[eq35]](/images/law-of-large-numbers__54.png) But
the covariances are absolutely summable, so
thatwhere
But
the covariances are absolutely summable, so
thatwhere
![]() is a finite constant.
Therefore,
is a finite constant.
Therefore,![]() Now
we can apply Chebyshev's inequality to the sample mean
Now
we can apply Chebyshev's inequality to the sample mean
![]() :for
any
:for
any
![]() (i.e., for any strictly positive real number
(i.e., for any strictly positive real number
![]() ).
Plugging in the values for the expected value and the variance derived above,
we
obtainSinceand
).
Plugging in the values for the expected value and the variance derived above,
we
obtainSinceand![]() then
it must be that
also
then
it must be that
also![]() Note
that this holds for any arbitrarily small
Note
that this holds for any arbitrarily small
![]() .
By the definition of convergence in probability, this means that
.
By the definition of convergence in probability, this means that
![]() converges in probability to
converges in probability to
![]() (if you are wondering about strict and weak inequalities here and in the
definition of convergence in probability, note that
(if you are wondering about strict and weak inequalities here and in the
definition of convergence in probability, note that
![]() implies
implies
![]() for any strictly positive
for any strictly positive
![]() ).
).
Chebyshev's Weak Law of Large Numbers for correlated sequences has been stated
as a result on the convergence in probability of the sample
mean:
However, the conditions of the above theorem also guarantee the mean square
convergence of the sample mean to
![]() :
:![]()
In the above proof of Chebyshev's Weak Law
of Large Numbers for correlated sequences, we proved
that![]() and
that
and
that
![]() This
implies
This
implies![]() Thus,
taking limits on both sides, we
obtain
Thus,
taking limits on both sides, we
obtain![]() But
But
![]() so
it must be
that
so
it must be
that![]() This
is just the definition of mean square convergence of
This
is just the definition of mean square convergence of
![]() to
to
![]() .
.
Hence, also in Chebyshev's Weak Law of Large Numbers for correlated sequences, convergence in probability descends from the fact that convergence in mean square implies convergence in probability.
A LLN is called a Strong Law of Large Numbers (SLLN) if the sample mean converges almost surely.
The adjective Strong is used to make a distinction from Weak Laws of Large Numbers, where the sample mean is required to converge in probability.
Among SLLNs, Kolmogorov's is probably the best known.
Proposition (Kolmogorov's
SLLN)
Let
![]() be an iid sequence of random
variables having finite
mean:
be an iid sequence of random
variables having finite
mean:![]() Then,
a Strong Law of Large Numbers applies to the sample
mean:
Then,
a Strong Law of Large Numbers applies to the sample
mean:![]() where
where
![]() denotes almost sure convergence.
denotes almost sure convergence.
See, for example, Resnick (1999) and Williams (1991).
In Kolmogorov's SLLN, the sequence
![]() is required to be an iid sequence. This requirement can be weakened, by
requiring
is required to be an iid sequence. This requirement can be weakened, by
requiring
![]() to be stationary and ergodic.
to be stationary and ergodic.
Proposition (Ergodic
Theorem)
Let
![]() be a stationary and
ergodic sequence of random variables having
finite
mean:
be a stationary and
ergodic sequence of random variables having
finite
mean:![]() Then,
a Strong Law of Large Numbers applies to the sample
mean:
Then,
a Strong Law of Large Numbers applies to the sample
mean:![]()
See, for example, Karlin and Taylor (1975) and White (2001).
The LLNs we have just presented concern sequences of random variables. However, they can be extended in a straightforward manner to sequences of random vectors.
Proposition
Let
![]() be a sequence of
be a sequence of
![]() random vectors, let
random vectors, let
![]() be their common expected value
andtheir
sample mean. Denote the
be their common expected value
andtheir
sample mean. Denote the
![]() -th
component of
-th
component of
![]() by
by
![]() and the
and the
![]() -th
component of
-th
component of
![]() by
by
![]() .
Then:
.
Then:
a Weak Law of Large Numbers applies to the sample mean
![]() if and only if a Weak Law of Large numbers applies to each of the components
of the vector
if and only if a Weak Law of Large numbers applies to each of the components
of the vector
![]() ,
that is, if and only
if
,
that is, if and only
if![]()
a Strong Law of Large Numbers applies to the sample mean
![]() if and only if a Strong Law of Large numbers applies to each of the components
of the vector
if and only if a Strong Law of Large numbers applies to each of the components
of the vector
![]() ,
that is, if and only
if
,
that is, if and only
if![]()
This is a consequence of the fact that a vector converges in probability (almost surely) if and only if all of its components converge in probability (almost surely). See the lectures entitled Convergence in probability and Almost sure convergence.
Below you can find some exercises with explained solutions.
Let
![]() be an IID sequence.
be an IID sequence.
A generic term of the sequence has mean
![]() and variance
and variance
![]() .
.
Let
![]() be a covariance stationary sequence such that a generic term of the sequence
satisfies
be a covariance stationary sequence such that a generic term of the sequence
satisfies![]() where
where
![]() .
.
Denote by
the
sample mean of the sequence.
Verify whether the sequence
![]() satisfies the conditions that are required by Chebyshev's Weak Law of Large
Numbers. In the affirmative case, find its probability limit.
satisfies the conditions that are required by Chebyshev's Weak Law of Large
Numbers. In the affirmative case, find its probability limit.
By assumption the sequence
![]() is covariance stationary. So all the terms of the sequence have the same
expected value. Taking the expected value of both sides of the
equation
is covariance stationary. So all the terms of the sequence have the same
expected value. Taking the expected value of both sides of the
equation![]() we
obtainSolving
for
we
obtainSolving
for
![]() ,
we
obtain
,
we
obtain![]() By
the same token, the variance can be derived
from
By
the same token, the variance can be derived
from![[eq78]](/images/law-of-large-numbers__121.png) which,
solving for
which,
solving for
![]() ,
yieldsNow,
we need to derive
,
yieldsNow,
we need to derive
![]() .
Note
thatThe
covariance between two terms of the sequence
is
.
Note
thatThe
covariance between two terms of the sequence
is![[eq83]](/images/law-of-large-numbers__126.png) The
sum of the covariances
isThus,
covariances tend to be zero on
average:and
the conditions of Chebyshev's Weak Law of Large Numbers are satisfied.
Therefore, the sample mean converges in probability to the population
mean:
The
sum of the covariances
isThus,
covariances tend to be zero on
average:and
the conditions of Chebyshev's Weak Law of Large Numbers are satisfied.
Therefore, the sample mean converges in probability to the population
mean:
Karlin, S. and H. E. Taylor (1975) A first course in stochastic processes, Academic Press.
Resnick, S. I. (1999) A probability path, Birkhauser.
White, H. (2001) Asymptotic theory for econometricians, Academic Press.
Williams, D. (1991) Probability with martingales, Cambridge University Press.
Please cite as:
Taboga, Marco (2021). "Law of Large Numbers", Lectures on probability theory and mathematical statistics. Kindle Direct Publishing. Online appendix. https://www.statlect.com/asymptotic-theory/law-of-large-numbers.
Most of the learning materials found on this website are now available in a traditional textbook format.