Given a number of observations, their sample variance measures how far they are spread apart. It is also an estimator of the variance of the population from which the observations have been drawn.
![]()
Given
![]() observations
observations
![]() having sample
mean
having sample
mean![[eq2]](/images/sample-variance__3.png) there are two main ways to compute the sample variance:
there are two main ways to compute the sample variance:
unadjusted sample variance, also
called biased sample
variance:![[eq3]](/images/sample-variance__4.png)
adjusted sample variance, also
called unbiased sample
variance:![[eq4]](/images/sample-variance__5.png)
Suppose we observe four
realizations:![]()
Their sample mean
is:![[eq6]](/images/sample-variance__7.png)
Dividing the sum of squared deviations from the mean by the number of
observations, we obtain the unadjusted sample
variance:![[eq7]](/images/sample-variance__8.png)
Dividing it by the number of observations minus one, we instead obtain the
unbiased
estimate:![[eq8]](/images/sample-variance__9.png)
When there are many observations, it may be convenient to organize the calculations into a table.
In the previous example, the calculations could have been performed as follows.
| Observation number | Value | Deviation from mean | Squared deviation |
|---|---|---|---|
| 1 | 4 | -1 | 1 |
| 2 | 4 | -1 | 1 |
| 3 | 5 | 0 | 0 |
| 4 | 7 | 2 | 4 |
| Sum | 20 | 0 | 6 |
| Divide sum by n | 5 | 3/2 | |
| Divide sum by n-1 | 2 |
The sample variances are on the last two rows of the table.
The sample variance is a measure of dispersion of the observations around their sample mean.
A squared deviation quantifies how far an observation is from the mean.
The sample variance, being an average of the squared deviations, measures the average distance (or spread) from the mean.
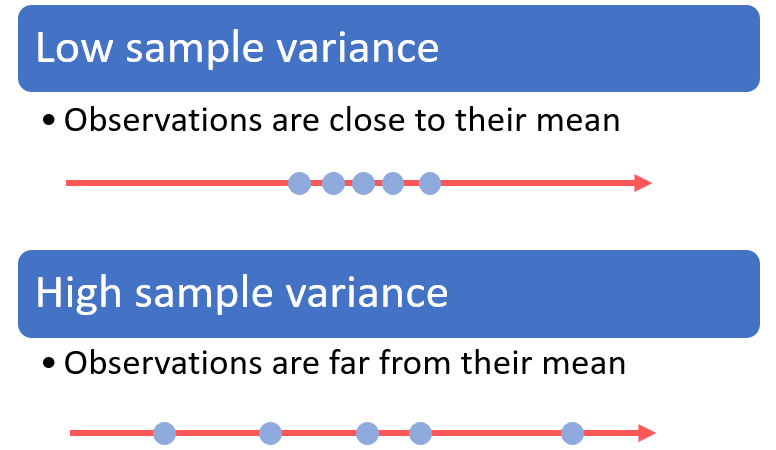
Assume that the observations are all drawn from the same probability distribution.
Then, the variance of that probability distribution is called population variance.
When the
![]() observations are independent,
observations are independent,
![]() is a biased estimator of the population
variance, while
is a biased estimator of the population
variance, while
![]() is unbiased.
is unbiased.
The lecture entitled Variance estimation provides more details about the sample variance, including derivations of its properties, examples and exercises.
Previous entry: Sample space
Next entry: Score vector
Please cite as:
Taboga, Marco (2021). "Sample variance", Lectures on probability theory and mathematical statistics. Kindle Direct Publishing. Online appendix. https://www.statlect.com/glossary/sample-variance.
Most of the learning materials found on this website are now available in a traditional textbook format.